【案例分享】HACMP NODE ID一致导致故障宕机
故障描述:
前些天在论坛闲逛,发现一兄弟的帖子 Power HA 其中一台异常宕机 点进去一看,发现故障描述和报错信息和我之前遇到的完全一样,基于提醒和血的教训,特将该问题编写成案例,希望大家引以为戒!
我们生产环境有PowerVM虚拟化后的AIX虚拟机2台,灾备环境有PowerVM虚拟化后AIX虚拟机1台,三台虚拟机通过PowerHA XD(基于SVC PPRC远程复制)搭建了跨中心高可用环境,操作系统版本为7.1.2.3,HA版本为7.1.2.6,搭建该环境之前,生产环境的两台AIX是通过HAMCP搭建了本地的高可用环境,为了灾备建设需求,将本地的1台主机通过alt_disk_copy的方式复制了一份rootvg至外置存储,并将该外置存储通过SVC PPRC复制至灾备存储卷当中,灾备的虚拟机再挂载该卷,并通过该卷启动操作系统。这样三台AIX虚拟机再重新搭建了PowerHA XD,实现跨中心HA热备。
通过这种方式,我们搭建了三套系统,均通过了HA切换测试,但是运行了一段时间后,其中一套系统的主机故障宕机(关机),资源组切向了备机,发现问题后,第一时间查看errpt日志,如下(这里借用 Power HA 其中一台异常宕机 帖子中的日志截图)
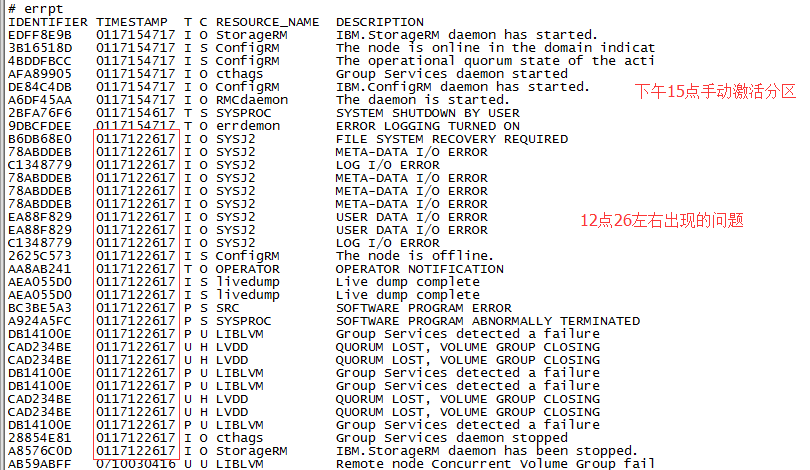
故障分析:
由于操作系统没有开always allow dump,所以并没有产生dump文件,当时分析了很久日志,很是疑惑不解,最终只能提交给IBM后台进行分析,后台也是许多天都没有答复。过了一个星期后,第二套系统也出现了一样的现象,一样的故障,造成主备HA切换,我开始怀疑是HACMP XD实施问题,立马翻阅了一下实施文档,发现在做alt_disk_copy时只用了alt_disk_copy -d hdiskx,后面并没有用-O -B -C参数,这些参数主要是用来复制rootvg时,删除原操作系统的配置信息和ODM库的一些信息,这样一来可能就会造成生产主机和灾备备机的操作系统某些信息一致。基于这种怀疑,我复看了errpt报错记录,宕机的主要原因应该是以下几个点:
IBM.StorageRM daemon has been stopped
Group Services daemon stopped
Group Services detected a failure
QUORUM LOST,VOLUME GROUP GROUP CLOSING
猜想是否是QUORUM中保留的两个主备节点信息一致,导致QUORUM关闭。
接着在生产主机运行命令
odmget -q "attribute='node_uuid'" CuAt
输出:CuAt: name = "cluster0" attribute = "node_uuid" value = "673018b0-7a70-11e5-91fa-f9fe9b9bc3c6" type = "R" generic = "DU" rep = "s" nls_index = 3
在灾备主机运行命令odmget -q "attribute='node_uuid'" CuAt
输出:CuAt: name = "cluster0" attribute = "node_uuid" value = "67301842-7a70-11e5-91fa-f9fe9b9bc3c6" type = "R" generic = "DU" rep = "s" nls_index = 3
生产主机运行命令
/usr/sbin/rsct/bin/lsnodeid
灾备主机运行命令
/usr/sbin/rsct/bin/lsnodeid
以上发现两个节点的RSCT NODE ID 完全一致
这就是造成信息冲突的点,造成了主服务停止和QUORUM仲裁关闭的元凶。
故障解决:
1.将PowerHA XD的HA服务全部关闭,禁止HA组服务的保护,并运行命令
/usr/sbin/rsct/bin/hags_stopdms -s cthags
/usr/sbin/rsct/bin/hags_disable_client_kill -s cthags
2.停止HA的ConfigRM服务和cthags服务
stopsrc -s IBM.ConfigRM stopsrc -s cthags
3.重新配置RSCT节点
/usr/sbin/rsct/install/bin/recfgct
4.重启所有3台操作系统
shutdown -Fr
5.启动HACMP服务和资源组,并检查RSCT NODE ID
通过以上方法,彻底解决了三套系统的HACMP主机宕机问题,建议以后做类似alt_disk_copy时,一定要带上-B -C -O参数,保持新操作系统的洁净,以防碰到类似的莫名其妙的问题。
7同行回答
如果nodeid碰到BUG recfgct重新生成不了 odmdelete -q "name=cluster0" CuAt,然后mknodeid -f 重新生成一下
收起你看到的帖子是我发的,我怀疑是rsct的bug
收起- 你有没有确认RSCT NODE ID是否一致?因为你的帖子描述来说,是同一人实施,有无可能实施者为了安装方便,直接克隆和安装的。
- 我这里的三套系统都是因为这,均发生了故障,故障报错也都一致,最后发现问题后,用命令检查,均发现是RSCT NODE ID一致,最后按照上面的方法,顺利解决了,后面再也没有故障宕机了。
