
大总结:双活数据中心建设系列之---基于SVC的三种主流双活数据中心架构深入探讨
作为业务系统的最后一道防线,IT数据灾备中心必须在极端状况下确保重要业务系统稳定运行。灾备方案的出现给业务系统提供了完备的数据级保护。然而,传统的灾备方案中存在着资源利用率低、可用性差、出现故障时停机时间长、数据恢复慢、风险高等问题。数据是否安全、业务是否连续运行无中断成为用户衡量灾备方案的关键。作为灾备方案中的高级别的双活数据中心解决方案,成为应对传统灾备难题的一把利剑。
传统的数据中心环境下,灾备生产中心长年处于休眠状态,并不参与前端应用的数据读写工作。如果数据中心环境良好,没有突发性灾难的发生,灾备中心资源就一直处于闲置状态,造成用户投资浪费。而在双活解决方案中,分布于不同数据中心的存储系统均处于工作状态。两套存储系统承载相同的前端业务,且互为热备,同时承担生产和灾备服务。这样不仅解决了资源长期闲置浪费的大问题,还能使数据中心的服务能力得到双倍提升。
在这样的背景下,传统的数据灾备中心越来越不能满足客户的要求,用户希望在成本可控的同时,建立高可靠性、高可用性、高可切换性的双活数据中心。
IBM SVC在双活数据中心建设的虚拟化存储解决方案中,有三种主流的双活基础架构可以满足我们搭建新形势下高要求的双活数据中心,值得我们深入探讨,分别为:SVC Stretch Cluster、SVCHyperSwap和SVC Local VDM+SVC PPRC。这三种架构方案针对不同的企业需求均能发挥最大的效用,本期专题讨论会就是要把这三种架构方案聊透彻,讲明白,让企业在选择时有所依据,有的放矢,并充分挖掘自身企业的思维方式,选择最适合自身企业发展的双数据中心虚拟化存储解决方案。
在本期讨论会上,大家针对“基于SVC的三种主流双活数据中心架构”的话题踊跃发言,提出了许多宝贵的观点和意见,现在我将分享、各类议题观点和各类问题及回答进行梳理总结,如有疏漏,还请不吝赐教。
主要分为以下五个方面:
一、三种SVC双活数据中心虚拟化存储解决方案的架构与特性方面
二、多种SVC双活数据中心建设方案与非SVC方案的对比方面
三、双活数据中心间链路与带宽方面
四、虚拟化云时代,是采用分布式还是集中式管理方面
五、SVC同城容灾与异地容灾方面
六、私有云建设与双活建设架构、案例方面
总结格式为:
【方面】
【分享】
【议题】
【观点】
【问题】
【疑问】
【问题解答】
一、三种SVC双活数据中心虚拟化存储解决方案的架构与特性方面
【分享】SVC Stretch Cluster
SVC Stretch Cluster也就是SVC拉伸式集群架构,就是把同一SVC集群中的SVC节点分散在不同的两个数据中心,它们之间通过光纤链路连接,并且需要第三地的仲裁设备。为了帮助大家深入理解SVC Stretch Cluster,先来理解下SVC Local Cluster:
一套SVC集群最少包含2个节点,最大8个节点,两两节点组成一个I/O group,因此一套SVC集群最大可以包含4个I/O group,如下图所示:
每一个存储LUN都分配给一个I/O group,你也可以手动转换存储LUN的I/O group,比如说LUN1属于I/O group0,当I/O group完全不可用时,需要手动转换至I/O group1,因为每一个I/O group均由两个SVC节点组成,所以每个存储LUN均分配给一个优先的节点和一个非优先节点,如下图所示: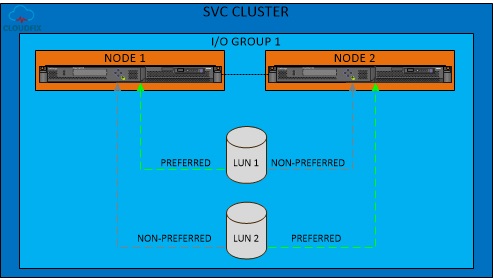
不同的存储LUN的优先节点可以不一样,这是SVC集群系统自动负载和分配的,同一SVC I/O group节点均衡负载着存储LUN,对于读I/O请求来说,来自于优先的SVC节点,而写I/O请求在同一I/O group的两个节点间同步,一次SVC I/O写请求,分解为以下5个步骤:
1.主机发送写I/O请求至SVC I/O group
2.优先的SVC节点A写入I/O至缓存,并发送I/O至同一I/O group的另一SVC节点B
3.节点B将写入I/O至缓存后,并回响应至节点A
4.节点A收到节点B的回响应后,向主机回响应
5.节点A将缓存写I/O写入LUN当中
写I/O流转图如图所示: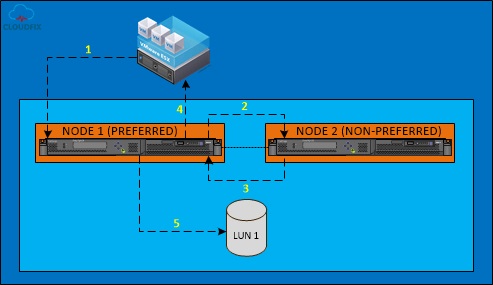
有人会说了,第5步最后才将缓存数据写入LUN当中,那么当还没有写LUN时,SVC节点突然断电了怎么办?这种情况SVC也是考虑了,每个SVC节点均配备了UPS电源,可以维持供电,可以保证缓存数据正常写入LUN当中。
基于以上这种机制,同一I/O group的两个SVC节点是实时同步的,当I/O group中的主节点故障时,另一SVC节点将接管,并进入写直通模式,并禁止写缓存,也就是说只有1、5、4三个步骤。
以上是SVC的I/O group在一个数据中心的情况,而SVC Stretch Cluster则是将一套SVC集群下的同一I/O group的两个节点拉开,分别放在两个数据中心,之前连接SVC的一套存储,拉开后各放置一套存储,通过SVC做vdisk镜像同步。说白了还是同一套SVC集群,同一个I/O group,SVC Local VDM(vdisk mirror)拉开成SVC Stretch VDM,映射给主机的volume还是同一个,这样一来就不难理解了。SVC、存储、主机及第三站点光纤连线下图所示: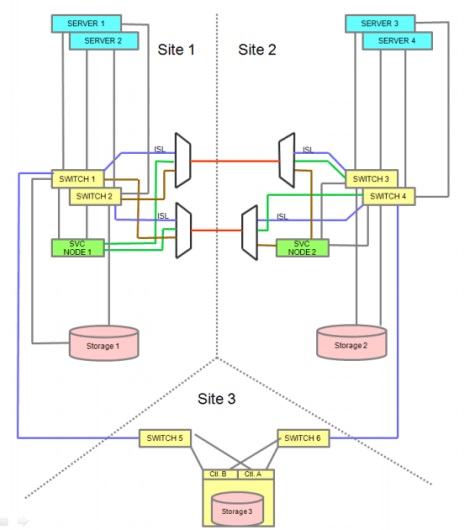
对于SVC Stretch Cluster来说,为了防范脑裂,仲裁站点是必需的。首先是configuration node,配置节点,是配置SVC集群后,系统自动产生的保存着所有系统配置行为的节点,不能人工更改配置节点,当配置节点失效后,系统会自动选择新的配置节点,配置节点十分重要,它对SVC节点仲裁胜利起着决定性作用,仲裁胜利的排序规则如下:
1.配置节点
2.距离仲裁站点近的节点
3.距离仲裁站点远的节点
下图为SVC Stretch Cluster两个站点的仲裁配置示意图: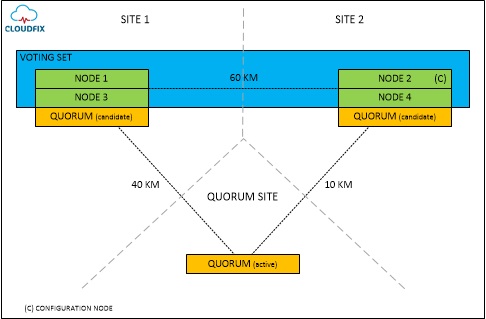
当两站点间光纤链路中断,第三站点仲裁节点活动时,脑裂发生,将通过投票仲裁选举获胜的站点,按照上述的仲裁胜利规则,configuration node位于节点2,选举站点2优先赢得仲裁,通过站点2恢复业务的正常存储访问。
当第三站点仲裁节点不活动时,不影响主机的正常存储访问,但是此时,两站点间光纤链路也中断了,发生脑裂,这时因为节点2为configuration node,它所拥有候选的Quorum将变为active Quorum,该Quorum选举站点2为仲裁胜利站点,通过站点2恢复业务的正常存储访问。
另外,SVC版本到了7.2时,又出了一个新功能, 叫做Enhanced Stretched Cluster,这又是什么呢?增强版拉伸集群增强点在哪?之前的Stretched Cluster看似实现了双活,实则只为数据级双活(SVC VDM),主机访问SVC实则只访问了一个I/O group优先节点,另一非优先节点则只是完成了写缓存同步的任务而已,无论是local cluster还是Stretched cluster,实际的读写卷操作并未通过非优先节点进行,通俗的说就是主备模式(ACTIVE-PASSIVE),由于优先节点是 SVC系统自动分配的,可能会出现一种情况是,主机在站点A,但是存储卷的优先节点却在站点B,主拷贝的存储却在站点A,主机一直访问了站点B的SVC节点,再访问站点A的存储,这样的存储路径完全不是最优的,对主机I/O性能造成影响,但是这些在Enhanced Stretched Cluster中均得到改善,实现了SVC双节点双站点读写双活,在该版本,元素均赋予site属性,如SVC节点、主机、存储等,不同站点的主机对各自站点的SVC节点和存储进行读写操作,对同一volume来说,站点A的主机访问站点A的SVC节点,站点A的存储,站点B的主机访问站点B的SVC节点,站点B的存储,存储访问路径最优,两个站点的SVC节点、主机、存储都同时活动,实现应用级双活(ACTIVE-ACTIVE),在site模式中,SVC优先节点概念不起作用了,配置了site模式的主机,优先访问活动的同site的SVC节点和同site的存储。如下图所示为读写模式下的Enhanced Stretched Cluster 流转图:
绿色的箭头为优先的读I/O流转,红色箭头为站点2的存储失效后的读I/O流转。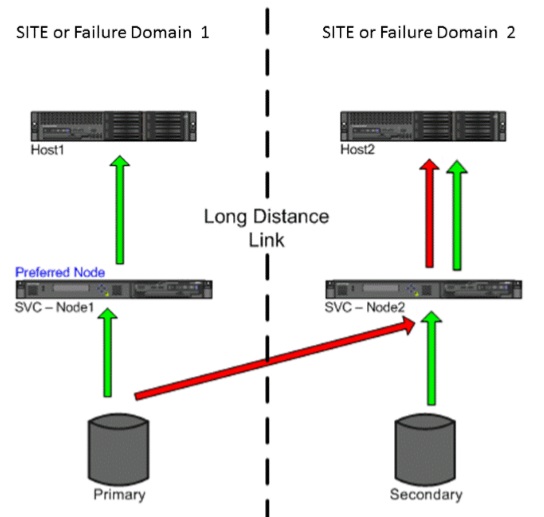
绿色的箭头为优先的写I/O流转,红色箭头为站点1/2的存储失效后的写I/O流转。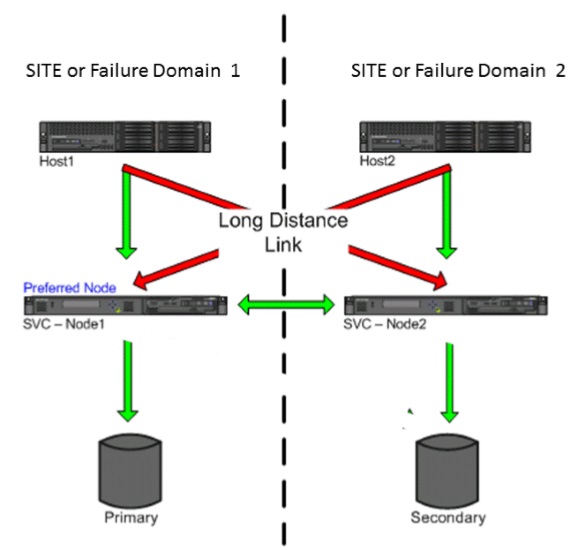
需要注意是,在写操作时,两个站点的SVC节点的缓存是保持同步的,但是不同于SVC LOCAL CLUSTER,整个写操作的过程中,SVC节点的写操作响应在写入缓存后就发生了,而不需要等待另一SVC节点写缓存完成并回复响应,这样一来,优化了整个写性能,具体过程如下:
1.主机向SVC写I/O请求。
2.同站点的SVC节点将写I/O写入缓存,并向主机回复响应,同时将写I/O同步至另一站点的SVC节点。
3.另一站点的SVC节点将写I/O写入缓存,并回复响应。
两个站点的SVC节点陆续将缓存写入各自站点的存储当中。
【分享】SVC HyperSwap
说到HyperSwap技术,在没有SVC存储虚拟化方案之前,HyperSwap技术主要用于IBM高端DS8000系列存储当中,达到应用和存储的高可用和双活需求,但是当时DS8000系列存储成本高昂,适用于核心类或者关键类应用的跨站点双活需求,不利于整体性的双活数据中心规划和建设,更别谈异构存储的跨中心双活建设了。但到了SVC 7.5版本,SVC和V7000都可以支持HyperSwap技术了,中端存储的地位瞬间提升了一个档次,异构的各类中端存储,结合SVC HyperSwap,都可以实现跨中心的双活高可用了,那么究竟SVC HyperSwap是什么技术?先来看看下面这张官方架构图: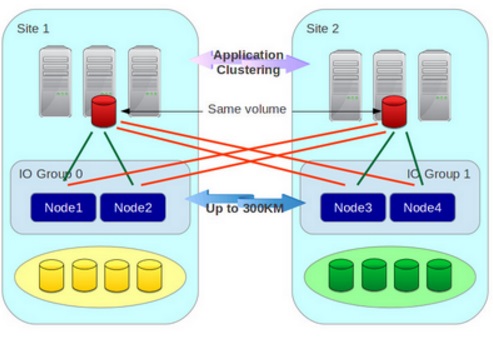
从图中可以看到的是,先从架构上:
SVC HyperSwap采用了hyperswap的拓扑架构,最少需要两个I/O Group,同一I/O Group需要两个节点,并在同一个站点,而且很惊喜的发现,每个站点均有VDISK,主机映射了四个SVC节点,存储路径更多了,冗余性更高了。
而SVC Stretched cluster采用的是stretched的拓扑架构,一个站点一个SVC节点,最大可达4个I/O Group,但是同一I/O Group的两个节点被分割到两个站点。两个站点的存储通过SVC虚拟化后只有一个VDISK,主机还只是映射两个SVC节点。
再从性能上:
SVC HyperSwap利用了更多的资源(包括SVC节点,线路和SAN交换机端口等),每个站点均含有完全独立的SVC读写缓存,一个站点失效,另一站点也能提供完全的性能,因为读写缓存在一站点失效后,不会被DISABLE,两个站点的读写缓存是独立的两套,这点特别重要。
而SVC Stretched cluster占用了相对较少资源,能提供更多的VDISK(同一SVC I/O Group VDISK划分有上限),但是当一站点SVC节点失效后,另一站点的读写缓存会被DISABLE,进入写直通模式,性能相对来说会下降,在某些情况下,比如后端存储性能不够强,缓存不够大等。而且主机的存储访问路径会减少一半。
另外一个主要不同点是,SVC HyperSwap有了Volume Groups这样概念,它能够将多个VDISK组合,共同保持高可用和数据的一致性,这对于需要映射多个VDISK的主机来说会有很大帮助,假设以下场景(主机映射多个VDISK):
1.站点2失效。
2.应用仍然从站点1进行读写,只在站点1进行数据更新。
3.站点2恢复。
4.站点1的VDISK开始同步至站点2的VDISK
5.站点1在VDISK同步时突然失效。
如果主机的多个VDISK没有配置Volume Groups,主机将很大可能无法通过站点2的数据恢复业务,因为站点2的多个VDISK正在被同步,尚未同步完成,它们的数据并不在同一时间点,挂在起来无法使用,那么这样的话只能寄希望于站点1。
但是如果主机的多个VDISK配置成Volume Groups,主机是能通过站点2的数据进行恢复的,虽然数据尚未同步完成,但多个VDISK间的数据一致性是可以保证的,仍然属于可用状态,只不过数据不完全而已。
与SVC Stretched cluster类似的是,SVC HyperSwap中的主机、SVC节点和存储均被赋予了站点属性,同时也需要配备第三站点作为防范脑裂的仲裁站点。
接着看下面这张图: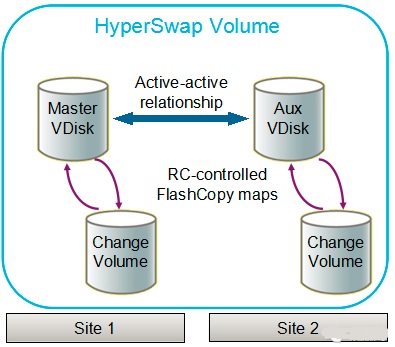
可以看见,一个hyperswap卷是由以下几个部分组成:
1.4个VDISK(可以是THICK/THIN/COMPRESSED,也可以被加密)
2.1个ACTIVE-ACTIVE的REMOTE COPY RELATIONSHIP(系统自己控制)
3.4个FLASH COPY MAPS(FOR CHANGE VOLUMES)(系统自己控制)
4.额外的ACCESS IOGROUP(方便IO GROUP FAILOVER)
基于该hyperswap卷技术,实现了两个站点VDISK的ACTIVE-ACTIVE。站点1的MASTER VDISK写入变化时,被写入站点1的Change Volume中(基于FLASH COPY,变化数据写入快照目标卷,原卷数据不变),站点2的AUX DISK写入变化时,同样被写入站点2的Change Volume中。一段时间后,系统自动停止VDISK与Change Volume间的快照关系,Change Volume将回写变化数据至VDISK,VDISK将通过SVC PPRC(REMOTE COPY)同步变化数据至另一站点的VDISK中,之后,站点VDISK又将重新与Change Volume建立快照关系,与根据这一原理,不断往返变化数据,保持四份COPY数据的同步的关系,当然这些都是SVC hyperswap系统自动完成的,用户无需干预。
另外,在hyperswap的卷复制ACTIVE-ACTIVE关系中,我们可以看到依然存在MASTER或者AUX的标签,对于主机来说,两个站点的其中一个I/O Group的VDISK是作为PRIMARY,提供读写,所有读写请求必须经过该I/O Group,然而hyperswap会自动决定是本站点的I/O Group的VDISK作为PRIMARY,还是主要承担I/O流量的I/O Group的VDISK作为PRIMARY。在首次创建hyperswap卷和初始化后,被标签为MASTER的VDISK作为PRIMARY,但是如果连续10分钟以上主要I/O流量是被AUX的VDISK承担,那么系统将会转换这种MASTER和AUX的关系,从这点上也可以看出与SVC Stretched cluster的不同,虽然SVC节点一样被赋予站点属性,但SVC hyperswap在另一站点仍然活动时,不局限于只从本地站点读写,它会考量最优存储访问I/O流量,从而保持整个过程中主机存储读写性能。另外需要注意的是主要的I/O流量是指扇区的数量而不是I/O数量,并且需要连续10分钟75%以上,这样可以避免频繁的主从切换。
上面讲了这么多,那么SVC hyperswap的读写I/O又是如何流转的呢?
读I/O见下图: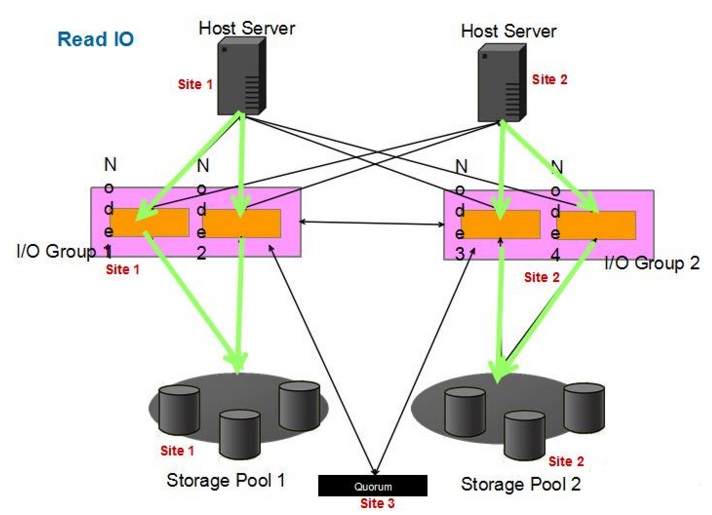
可以看到,每个站点第一次HyperSwp初始化后,先各自从各自站点的SVC节点读操作,绿色线为读操作I/O流转。
写I/O见下图: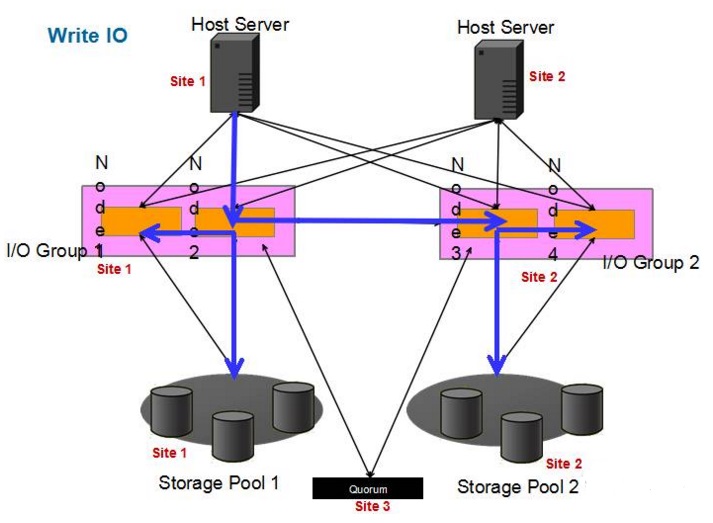
可以看到,图中显示为站点1的主机一次写I/O全过程:
1.主机向本站点1的其中一个SVC节点发送写I/O请求。
2.该SVC节点2将写I/O写入缓存,并回复主机响应。
3.该SVC节点2将写I/O写入节点1缓存,并同时发送写I/O至站点2的节点3和节点4。
4.SVC节点1、3、4回复节点2的响应。
5.两个站点的SVC节点分别将缓存写入各自站点的存储当中。
【分享】SVC Local VDM+SVC PPRC
上面通过大量篇幅介绍了SVC Stretched Cluster和SVC HyperSwap,这两种存储虚拟化双活数据中心解决方案均为ACTIVE-ACTIVE模式SVC方案,那么SVC Local VDM+SVC PPRC又是什么?SVC Local VDM即本地SVC VDISK MIRROR,跟Stretched Cluster方案采用了类似的存储复制技术,只不过是本地非跨站点的VDM,又跟SVC HyperSwap方案采用了相同的SVC PPRC远程复制和Consistency一致性组技术,而且对SVC的版本没有很高的要求,SVC 6.4版本就可以实现,可以说是另外两种技术的爸爸,另外两种技术均是由它演变升级而来,既然是较老的技术,为什么还要再这里谈呢?还不是ACTIVE-ACTIVE,只是ACTIVE-STANDBY。
当然有必要,有以下几个必要点:
1.利用SVC Local VDM+SVC PPRC可以实现本地双同步数据保护+灾备同步数据保护,还很容易实现异地异步数据保护。充分保护本地级存储数据,和本地可靠性。
2.结合PowerHA EXTEND DISTANCE(PowerHA XD)很容易实现本地双主机+灾备主机热备。本地主机故障,本地主机互相切换,本地双主机故障,主机和存储均切灾备主机和存储,十分灵活,可将不同系统的主机分别布署在两个数据中心。两个数据中心均各自承担些许业务。
3.无需第三站点仲裁,第三站点对于大部分企业来说,都基本相当于虚设,怎么说呢,第三站点基本都放置于本地站点,本地站点故障时,第三方站点和本地站点相当于全部故障,需要人为干预,才能在灾备站点恢复业务,复杂度高。如果真正建立第三站点,又需要增加大量成本。
4.无需担心双中心间光纤光衰、线路延时、抖动甚至中断,充分保护本地站点系统的可靠性。发生脑裂时,基于HACMP XD,生产端的主机数多于灾备站点,发生脑裂仲裁时,生产站点总是会赢得仲裁胜利,将自动关闭灾备站点主机,生产站点不受任何影响。对于这种情况来说,如果是ACTIVE-ACTIVE方式的脑裂情况,特别是在将所有各类异构存储均接入SVC,通过两站点间SVC复制,脑裂现象的影响面将扩大至整个数据中心业务层面,而不是仅仅小部分业务造成中断。
那么,有人会说,题目是双活数据中心建设,SVC Local VDM+SVC PPRC不应该算是一种双活建设方案,只是实现了数据级存储双活。其实不然,利用该架构,实则实现了双活中心的基础架构,应用层双活可以通过配合软件架构的方式来实现,具体内容将在“双活数据中心建设系列之---基于软件架构的双活数据中心建设方案深入探讨”主题中详细探讨。先来看下该SVC方案的架构,如图所示: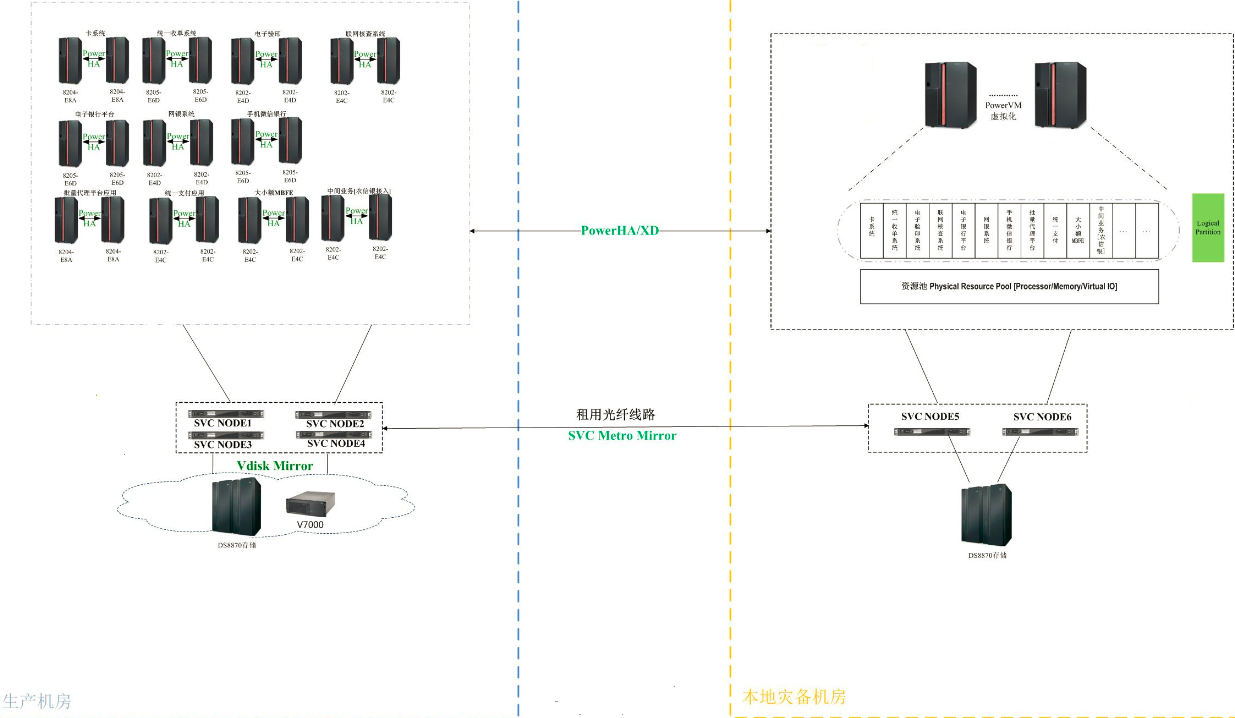
可以看到,该方案需要两套SVC集群,最少需要2个I/O Group,4个节点,本地和灾备各一套SVC集群,一个I/O Group,两个节点。该架构与HyperSwap架构有点类似,不同的是该架构本地站点的存储有两个,灾备站点存储为1个,本地站点两个存储通过SVC做VDM,本地站点和灾备站点存储通过两套SVC做SVC PPRC,实现了三份存储数据实时同步。本地站点两主机挂载本地站点的存储,灾备站点主机挂载灾备站点的存储,三台主机通过HACMP XD(基于SVC PPRC)实现跨站点高可用,当本地站点的主机故障时,自动切向本地备机,业务中断时长5分钟以内,具体根据HACMP切换时长;当本地站点主备机全部故障时,本地存储和本地主机均自动切向灾备主机,业务中断时长5分钟内,具体根据HACMP切换时长;本地一台备存储故障时,完全不受影响;本地一台主存储故障时,自动切往本地备存储,业务I/O中断1分钟以内。
另外,该架构的数据读写流转在上面的SVC LOCAL CLUSTER中已经详细介绍,只是多了在SVC I/O Group节点间写同步后,再同步一份写I/O至灾备I/O Group的两节点,这里不再赘述。
【议题1】SVC HyperSwap和SVC Stretch Cluster做为A-A模式的SVC虚拟化存储解决方案,有何缺陷或者风险?
【观点1】hyperswap不适合rac这种跨站点读写的双活
【观点2】据我了解到ESC模式下的iogroup并不是真正的冗余模式。比如我有两个iogroup,所有的业务都在iogroup1上,当第一个iogroup的两个节点都宕机的话前端业务也就中断了,业务并不会自动切换到iogroup2上。
【观点3】对的,SVC ESC只有两个节点,两个节点同时故障时,需要手动干预才能恢复业务,所以为了更高、更苛刻的冗余时,出现了SVC HYPERSWAP,但是实际情况两个SVC节点同时故障的情况还是非常少。
【观点4】还是需要看业务类型,比如oracle rac,dg,vmware等,不一样的业务要求不同。
【议题2】SVC Local VDM+SVC PPRC作为A-S模式的SVC虚拟化存储解决方案,有何缺陷或者风险?
【观点1】SVC Local VDM是作为本地高可用的解决方案,缺陷或者风险来讲如果同SVC PPRC只是作为本地数据高可用,无法做到容灾级别。
SVC PPRC是解决站点级别的灾备解决方案,所谓的缺陷是要跟谁去对比。比如作为存储复制解决方案跟数据库复制方案比,各有优缺点。
【观点2】SVC Local VDM+SVC PPRC做为数据级本地保护和容灾,结合HACMP只是ACTIVE-STANDBY,像数据库级别的复制,主要还是事物级别的TCPIP同步,性能和效率当然没有SVC VDM和PPRC高,但是一致性从事物层得到了保证,但是数据库复制技术也是有限制的,它主要是通过事物日志复制和对端重写来实现,但日志有时候也不能覆盖全部数据库操作,比如XML和LOB格式的字段,是没法通过日志复制传输的,有些应用为了执行效率高,对数据库采取了不记日志操作。
【问题1】
【疑问一】SVC的ESC拉伸双活模式Lun是否可以就近读写?hperswap模式是否可以就近读写?SVC的ESC拉伸双活模式Lun是否可以就近读写?hperswap模式lun是否可以就近读写?还是只能读对端lun?造成这个问题的原因是什么?
【问题解答一】SVC StretchCluster与SVC HyperSwap的最大特性就是SVC节点“站点化”,主机节点“站点化”,存储节点“站点化”,所以这两种模式都是同一站点的主机读写同一站点的SVC的节点,SVC节点读写同一站点的存储节点。
所以这两种ACTIVE-ACTIVE存储双活方案,是就近读写的,另外SVC HyperSwap不仅仅是就近读写,如果本地站点的IO流量连续10分钟低于25%,而对端站点的IO流量连续10分钟高于75%,那么SVC HyperSwap将反转读写关系,优先读写对端站点。
【疑问二】感谢解答,但我认为hyperwap双活模式下,不可以就近读写。两个站点都要去找该lun的owner站点去写,然后镜像到另一端缓存。因SVC与vplex的全局一致缓存不同SVC的hperswap是两套缓存表。正式因为这种情况,导致会有主机频繁写对端lun的情况出现,导致lun owner关系反转。 不知道我的看法是否正确?谢谢
【问题解答二】不对,1.SVC hperswap虽然是两套缓存表,但是缓存与缓存的同步是在SVC节点间进行的,与主机无关,主机只是读写同站点的SVC节点和存储,不会去读写另一站点的SVC节点,当主机写同站点的SVC节点后,SVC立即返回响应,表明已经完成写操作,剩余的缓存同步和落盘的事情由SVC内部完成。
2.SVC hperswap架构,每个站点都有各自的MASTER和AUX VDISK,主机优先读写MASTER VDISK,直到主机出现连续10分钟75%以上的I/O读写在AUX VDISK上,AUX和MASTER的关系将反转,基于这样一种机制,MASTER和AUX的关系不会不停的反转,而是既控制住了反转频率,又在MASTER VDISK站点出现性能问题时,能够及时反转关系,提升性能。
【问题2】
【疑问一】数据不完全,如何实现数据可用?
请问:"但是如果主机的多个VDISK配置成Volume Groups,主机是能通过站点2的数据进行恢复的,虽然数据尚未同步完成,但多个VDISK间的数据一致性是可以保证的,仍然属于可用状态,只不过数据不完全而已。"既然数据不完全,然后和实现可用?
【问题解答】1.多个VDISK配置成了Volume Groups的形式,那么两个站点的多个VDISK的一致性是同时的,也就是说站点1的多个VDISK同时写,站点2相应的多个VDISK写也是同时写的,这样一来,每次站点2的多VDISK写入后,从存储视角来说,多VDISK是数据一致性的,站点2的主机是能利用这一致性的多个VDISK的,在允许数据一定丢失的情况下,即使同步没有完成,还是可以利用的。而如果是主机拥有多个VDISK,但是这多个VDISK不配置成Volume Groups的话,两个站点仅仅是单个VDISK是一致性的,站点2的多个VDISK的同步时间戳不一样,不能保证多VDISK同时是一致性的,如果同步没有完成,那么站点2可能无法利用这些VDISK。
2.存储的一致性组是建立在存储视角的,假如是数据库的话,更好的办法是从数据库事物的层面保持一致性,但是当今存储没有谁能做到这一点。
【疑问二】还是没太明白,数据不完全跟数据可用如何理解?
【问题解答】主机对文件系统的一次写是对多个PV分别写,对吧?该站点的PV与站点2的PV同步时,如果没有配置同步卷组是不是同步有先有后?有可能这个卷已经同步了,那个卷还没有同步,那这时,站点1故障了,站点2的这些存储卷是不是得有逻辑错误了?是不是不可用了?那如果配置了同步卷组,站点2的的多个PV是一起同步的,本地站点的多个卷一次写操作,站点2的多个卷也是一起写的,是不是就是一致性卷组了?当站点1故障了,即使站点2还没有完全同步完,这些一致性卷组是不是没有逻辑问题了?是不是可用的?
【问题3】
【疑问一】IBM svc ESC和 hyperswapcache工作模式和lun的读写访问方式区别?EMC vplex的显著区别是什么?IBM svc ESC和 hyperswapcache工作模式和lun的读写访问方式区别?我们都知道EMC vplex metro是全局一致性缓存,缓存形式的不同,SVC和vplex在双活特性上带来了哪些不同?
【问题解答一】缓存形式的不同,VPLEX没有写缓存,这就意味着写性能会有一定的影响
【问题解答二】1.IBM svc ESC是SVC LOCAL CLUSTER的跨站点拉伸版,主要是利用了VDM的技术和原理,而SVC hyperswap主要利用了FLASH COPY和SVC PPRC技术和原理;SVC ESC缓存同步是在同一I/O GROUP的两个节点进行,而SVC HYPERSWAP既有同一I/O GROUP又有不同I/O GROUP的两个节点缓存同步
2.IBM svc ESC和SVC hyperswap读写方式均是就近原则,本站点读写本站点的SVC节点和存储。但SVC hyperswap较高级的地方在于,它会判断两个站点的读写I/O流量,如果某个站点I/O流量连续10分钟占比75%以上,那么它将反转MASTER VDISK和AUX VDISK的角色。
3.EMC vplex metro是全局一致性缓存,但它没有写缓存,虽然都是各自站点就近读写,但是增加了后端存储压力,写性能上可能会受影响。举例来说,像SVC+FLASH存储,在关闭了SVC写缓存的情况下,整个性能没有打开SVC写缓存高。
【疑问二】据我了解到ESC具有就近读写功能,HyperSwap没有这个功能吧?
【问题解答】两个都有就近读写功能,HYPERSWAP所需的SVC版本还比SVC ESC高,把SVC节点、存储和主机都站点化了,有更多的节点冗余和更多的性能优化。
【疑问三】PPRC是啥玩意?
【问题解答】point-to-point remote copy,也就是metro-mirror
【问题4】
【疑问一】SVC HyperSwap 和SVC Stretched Cluster适合哪些场景?
SVC HyperSwap 和SVC Stretched Cluster适合哪些场景?哪些场景选择SVC HyperSwap 更有优势?二者的性价比如何?
【问题解答一】首先这两者都是高可用解决方案中的两个技术代表
SVC HyperSwap可以说是对 SVC esc 技术灵活性的补充或者说是增强
具体来说V7K V5K 是无法做到的ESC的,同样IBM V9000也无法做到ESC.
而hyperswap技术对 V7K V5K V9000开启了大门,使这些产品也有高可用的特性。
【问题解答二】楼上正解,如果是没用SVC,仅仅用hyperswap技术,那么性价比肯定是V7K V5K V900之类的更高,只用存储就实现了跨中心存储双活。
如果用了SVC,hyperswap用了4个以上的SVC节点,Stretched Cluster只用了两个,但是hyperswap的性能和可靠性较Stretched Cluster有所增强,但Stretched Cluster又能扩展到今后的异地灾备,如果简单的以价格来区分两者的化,那么首选Stretched Cluster,如果要综合比较的话,两者真的不相伯仲,要看你的需求。
如果你不关心价格,就是要最好的高可用,最好的性能优化,对划分的卷上限1024也可以接受的,不要求将来实现扩展同城或者异地灾备的,运维技术也能保障,那就推荐hyperswap,如果你关心价格,对性能和高可用要求不那么苛刻,将来想实现异地或者同城灾备扩展的,那么推荐Stretched Cluster,但是SVC hyperswap和SVC Stretched Cluster都要求有第三站点仲裁,而且对两个站点间的链路的稳定性、可靠性、性能要求很高。
【疑问二】你好,esc用两个节点就够了吗,我看了一个文档,esc也推荐最少4个节点,2个为1个iogroup。4个节点比两个节点的优势有哪些呢?
【问题解答三】ESC最少两个节点,在主机较多、SVC节点负载较大的情况下,推荐4节点,甚至6节点、8节点,将I/O读写分散于不同的I/O GROUP上,如果仅仅是1个I/O GROUP,那么所有主机均通过这个I/O GROUP读写存储,是否负载能满足,是需要考虑的。从冗余上来说,1个I/O GROUP和2个I/O GROUP都是一样的。都是靠同一I/O GROUP的两个SVC节点来冗余的。
【问题5】
【疑问】V7000 HYPERSWAP实施请教
HyperSwap中如何保证数据的一致性吗?是如何配置的呢?
看到论坛里面说到SVC hyperswap通过VOLGRP数据的一致性,但是我在实施V7K (7.7.1.3)hyperswap时候,GUI中没看到volume group。
【问题解答】建议从CLI中配置HYPERSWAP
1.创建一致性组
例如:mkrcconsistgrp –name hsConsGrp0
2.创建master vdisk
例如:mkvdisk –name hsVol0Mas –size 1 –unit gb –iogrp 0 –mdiskgrp siteA-ds8k -accessiogrp 0:1
3.创建AUX vdisk
例如:mkvdisk –name hsVol0Aux –size 1 –unit gb –iogrp 1 –mdiskgrp siteB-ds8k
4.创建Change vdisk
例如:mkvdisk –name hsVol0MasCV –size 1 –unit gb –iogrp 0 –mdiskgrp siteA-ds8k -rsize 0% -autoexpand
例如:mkvdisk –name hsVol0AuxCV –size 1 –unit gb –iogrp 1 –mdiskgrp siteB-ds8k -rsize 0% -autoexpand
5.创建relationship
例如mkrcrelationship –master hsVol0Mas –aux hsVol0Aux –cluster testCluster -activeactive –name hsVol0Rel
6.开始同步
例如:mkrcrelationship –master hsVol0Mas –aux hsVol0Aux –cluster testCluster -activeactive –name hsVol0Rel –sync
或者7.创建relationship并加入一致性组
例如:mkrcrelationship –master hsVol0Mas –aux hsVol0Aux –cluster testCluster -activeactive –name hsVol0Rel –consistgrp hsConsGrp0
或者8.创建relationship并加入一致性组同步
例如:mkrcrelationship –master hsVol0Mas –aux hsVol0Aux –cluster testCluster -activeactive –name hsVol0Rel –consistgrp hsConsGrp0 -sync
9.建立master和AUX的VDISK与对应change vdisk的relationship
chrcrelationship –masterchange hsVol0MasCV hsVol0Rel
chrcrelationship –auxchange hsVol0AuxCV hsVol0Rel
完成
【问题6】
【疑问】SVC主流双活方式之一Stretch Cluster的实现方式
Stretch Clustr,也叫拉伸式集群,在该模式下,本地的A,B站点是双活的,远程C站点可以用Global Mirror实现两地三中心,请专家通过实例讲解这种双活方式实现双活的原理以及这种方式有没有风险?
【问题解答】1.实现双活原理:
svc stretch cluster是SVC LOCAL CLUSTER的拉伸版,其实现原理和技术主要是SVC VDM,它需要最少一套I/O GROUP,两个SVC节点作为需求,每个站点的主机均读写各自站点的SVC节点和存储,对于写操作来说,先写某个SVC节点的缓存,再将该缓存同步至另一站点的SVC节点中,最后分别落盘,在另一站点的主机写操作也是同样,为了保证两边存储写数据的一致型,不导致脏读,SVC用了锁排斥技术。另外SVC利用在双活的基础上,利用Global Mirror技术可以将SVC的数据异步地同步至异地站点的V7000、SVC等中。
2.风险
伴随着双活,风险也是当然的,没有哪一种技术是十全十美的,按照企业的需求都有用武之地,SVC Stretch cluster的风险在于同一I/O GROUP只有两个SVC节点,本地一个,灾备一个。本地SVC节点故障,则切往了灾备SVC节点,冗余度来说,本地有点单点的感觉;另外SVC Stretch cluster对两个站点间的链路要求很高,需要稳定度高,时延和抖动尽量小,如果两中心间链路中断,那么两个中心的SVC节点读写将HOLD住,直到第三站点仲裁选举出胜利站点,如果所有业务主机均通过SVC节点访问存储,所有业务将有一段时间被中断,中断时间取决于两个站点间距和仲裁时间。
【问题7】
【疑问】在一套SVC集群的,节点之间的缓存数据同步是通过什么途径进行的?是管理网络?是san存储?是fc链路?
【问题解答】通过fc链路。节点间通信走cluster zone内的端口,或者通过cli限定只走某些端口。
【问题8】
【疑问】关于lun和raid group的问题
划分lun时,一个lun可以来自不同的raid group吗?
【问题解答】可以
1.如果划LUN是通过普通存储化,没有经过SVC,那么每个LUN和POOL是对应的,POOL又跟RAID GOUP是对应的,只有RAID GROUP的RAID形式是一致的才能放到同一个POOL中(一个RAID GROUP对应一个MDISK),所以该LUN划分出来后,该LUN是经过了多个MDISK虚拟化之后的产物,BLOCK分布于多个MDISK上,所以可以来自多个相同RAID形式的RAID GROUP,但无法来自多个不同RAID形式的RAID GROUP
2.如果划LUN是通过SVC划出来的,但是底层存储通过IMAGE模式透穿至SVC的,也就是说底层存储LUN--->SVC LUN是一一对应的,这时SVC上的LUN在底层存储上的分布也是来源于相同RAID形式的RAID GROUP
3.如果划LUN是通过SVC划出来的,但是底层存储通过MANAGE模式映射给SVC管理的,如底层存储RAID 5组成如下一个逻辑关系:MDISK--->RAID 5 POOL--->存储LUN1--->SVC MDISK1,底层存储RAID 10组成如下一个逻辑关系:MDISK--->RAID 10 POOL--->存储LUN2--->SVC MDISK2,再通过SVC MDISK1和SVC MDISK2划出一个新的SVC VDISK,这时的SVC VDISK的BLOCK是分布于不同RAID形式的RAID GROUP的。
【问题9】
【疑问】SVC Local VDM和SVC PPRC数据同步的粒度是?是实时更新数据吗?
【问题解答】都是实时同步的,因为每次的写SVC节点的操作,都会要等待另一SVC节点的写响应,才会认为是一次完整的写操作周期。补充一点,同步的颗粒度是bitmap(位图)
【问题10】
【疑问】SVC管理的存储扩容,SVC会不会出现瓶颈?
目前的环境下面一套svc有一个IO GROUP,下面挂载了不同的存储,现在相对下面的挂载的存储扩容,担心随着后面存储容量的扩大,SVC会不会出现瓶颈?怎么判断?
【问题解答】上面这个问题来说,如果仅仅从后端挂载的存储容量扩容,SVC是会不出现性能瓶颈的,SVC最大支持4096个VDISK,如果后端存储扩容,划分出来的卷的数量也越来越多,甚至需要超过4096个VDISK,那么SVC仅仅是不再支持划分而已,性能不会出现问题。如果从SVC映射的主机数量角度来说,如果SVC映射的主机数量越来越多,那么均分至每一个SVC I/O Group优先节点的主机数量也越来越多,这时就需要考虑SVC节点的性能瓶颈,因为SVC节点的缓存容量有限,主机数量的增加意味着所有主机平均每次需要写入的IO量增多,假如增大至单个SVC节点缓存不足够容纳时,这时就会开始出现性能瓶颈,就需要开始新增SVC I/O Group了。
其实SVC的性能很不错,借用一下前人测试的结果:
“”单论SVC的节点性能,在前两代的CF8节点上做过SPC-1测试,16个V7000在8个CF8节点管理下,SPC-1性能达到50多万IOPS。现在最新的DH8节点,性能是CF8的3-4倍,那么性能可达到150-200万IOPS,每个I/O Group可达到50万IOPS。“”
我们可以利用监控来判断SVC节点是否已饱和,如TPC软件,也可以用SVC自身WEB界面上的监控来初步判断。
二、三种SVC双活数据中心建设方案与非SVC方案的对比方面。
【分享】三种SVC双活架构详尽对比
在上面的章节中,我们已经深入探讨了基于SVC的三种主流双活数据中心架构,详细的介绍了每种架构的基本模式、特性、原理和I/O读写等方面内容,为了更方便与直观的展示三种架构的区别和特性,列表如下: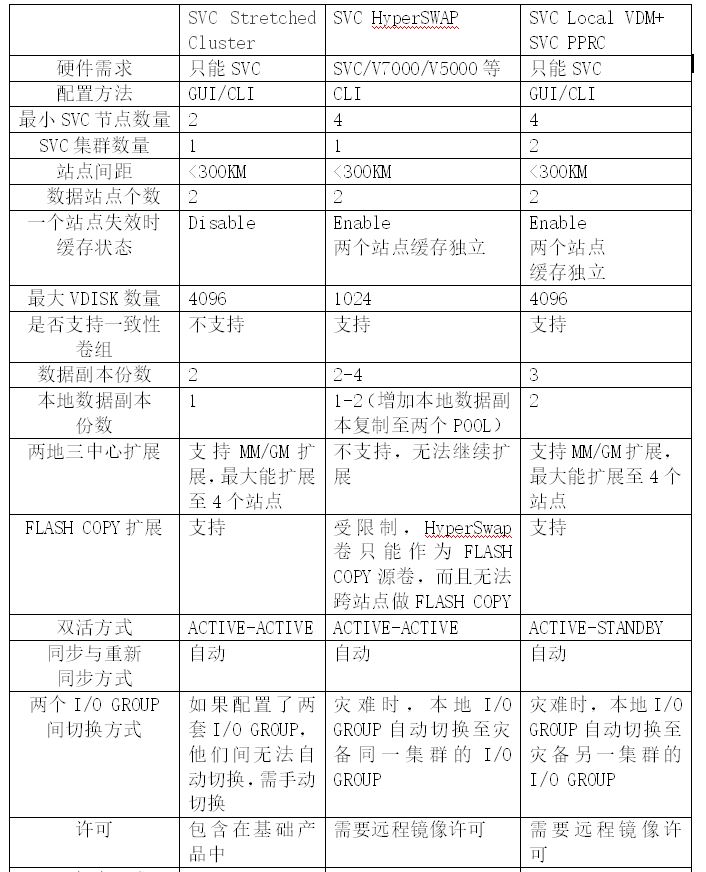
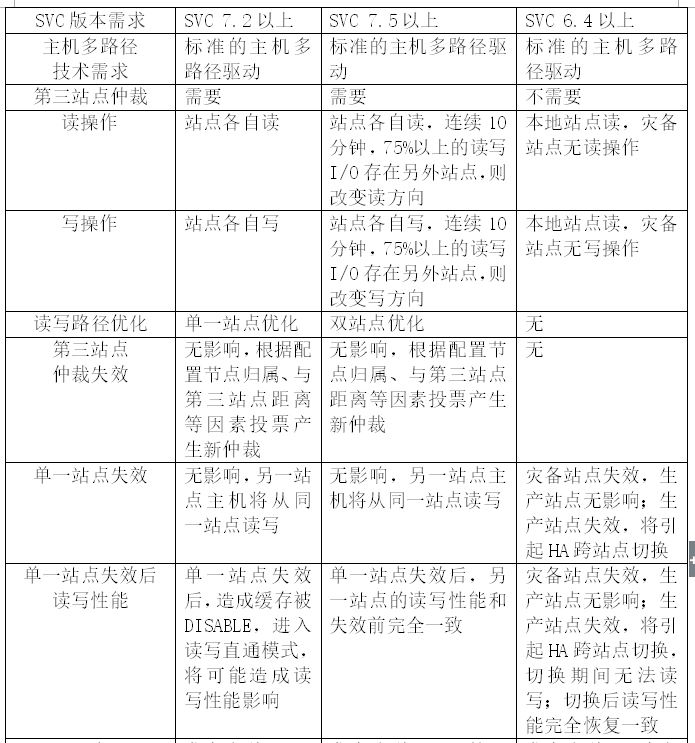
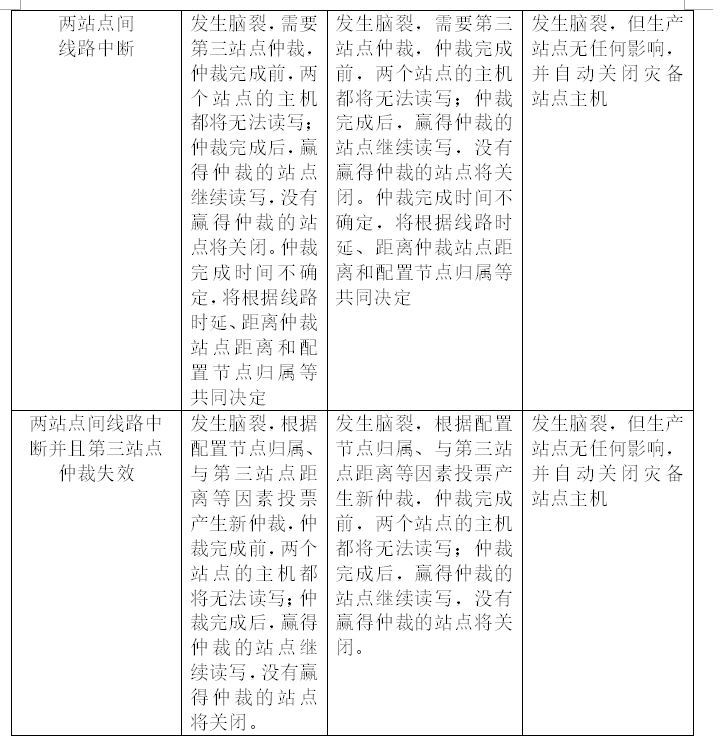
上面的列表很直观的展示了三种SVC架构的区别和共同点,可以看到,三种架构在不同的场景和不同的高可用要求下,均有用武之地。SVC Stretched Cluster和SVC HyperSWAP架构实现了双站点ACTIVE模式,但这两种模式有两个弊端,一是对数据库双活的实现,依旧需要配合数据库软件层的方案解决。二是对两个站点间的线路要求非常高,一旦线路中断(这种情况并非不可能,尤其在当下各种修路、修地铁,多家运营商的裸光纤都在同一弱电井,同时断的可能性大增),将对两个站点的所有主机均造成一段时间的影响,所有业务被中断,影响时间取决于仲裁时间和两站点间距离。而且还需要忍受站点间线路的时延和抖动的可能造成的影响,站点间距离越大,这种影响会被不断放大,影响读写性能,甚至造成线路中断。这种情况下反而不如用SVC Local VDM+SVC PPRC架构,从分保护了本地资源,排除了可能的不可抗拒的影响,而且如果采用了SVC Local VDM+SVC PPRC架构,虽然存储架构层作为ACTIVE-STANDBY方式,但仍旧可以配合软件层实现双活数据中心建设;另外SVC HyperSWAP架构看似很高级,无论从双站点的读写性能优化、单一站点失效后的全面保护能力方面还是双活架构后的高可用方面均优于Stretched Cluster,但却无法继续进行两地三中心扩展,实施复杂性也更高,运维成本也提高,而且总的VDISK数量较少等等;SVC Local VDM+SVC PPRC充分保护了本地,但是灾备的实施却又局限于AIX系统下的HACMP,6.1之前的AIX版本和linux、windows系统均无法实现跨站点高可用,只能从数据层同步,并利用软件层的方式实现高可用和双活。而且SVC Local VDM+SVC PPRC的一套SVC集群下的两个IO Group间无法自动切换,这点SVC Stretched Cluster也是如此,也就是说如果SVC Stretched Cluster配置为2个I/O Group,I/O Group间是无法实现自动切换的,需要人为手动切换;SVC Stretched Cluster实现了ACTIVE-ACTIVE,又可以扩展两地三中心,但是读写性能优化方面做得又不如SVC HyperSWAP,而且本地冗余度做得也不大好,本地一个SVC节点故障,本地就没有冗余保护,只能利用灾备站点的SVC节点,这点在SVC Local VDM+SVC PPRC和SVC HyperSWAP都得到了冗余度提升;另外还有一点共同点得我们关注,我们知道SVC Stretched Cluster、SVC Local VDM+SVC PPRC和SVC HyperSWAP均使用了同步复制技术,但有没有想过如果真的因为站点间距离长,时延比较大,导致两个SVC节点同步缓慢,以致最后影响双数据中心整个业务系统的写I/O缓慢。SVC还考虑到了这一点的,在SVC节点同步的参数中有mirrowritepriority属性,可以设置为latency,当同步响应时间大于5秒时,放弃同步,保证主站点/主存储的写I/O性能。基于此,三种方案针对不同的企业需求,不能说哪种方案通吃,也不能说哪种方案一定不行,都有使用优势和劣势。
**【问题1】
**SVC存储网关与友商类似产品的对比优劣势是什么?
【问题解答】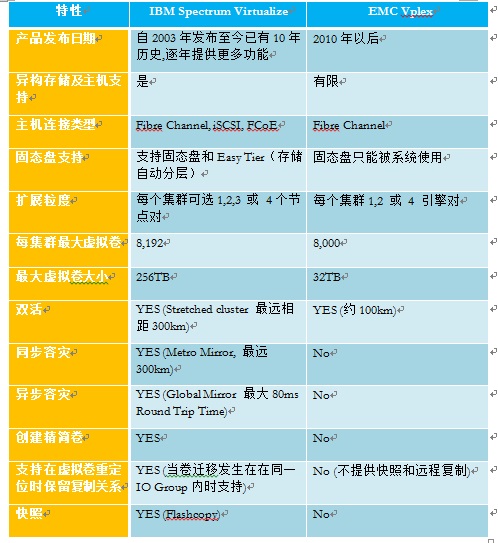
【问题2】
针对有些厂商的存储阵列自身带有双活+复制的功能,SVC的ESC的优势如何体现?现在有厂商存储阵列自带双活+复制功能,例如:A中心和B中心之间双活,B中心存储和C中心存储做复制,完全通过存储阵列自身实现。目前,IBM DS8000和SVC ESC+复制能够实现。但是ESC的IO GROUP中单节点故障严重影响性能,如何应对?
【问题解答】1.自带双活功能的存储算是少数,如DS8000+HYPERSWAP,即使有,也需要LICENSE,有的MM也要LICENSE,GM也要LICENSE,中低端存储就没办法了,像SVC这样把高中低端存储均融合后,用SVC ESC和SVC HYPERSWAP都实现了双活或者双活+异地。
2.SVC ESC的IO GROUP单节点故障,将引发节点切换,站点的主机将会访问另一站点的SVC节点,只是造成了短暂时间的访问中断而已,另一站点SVC节点接管后,性能不会出现明显的下降。这种方式并没有不妥,只是本地站点只有1个SVC节点,冗余性来说,有点不够。另外,SVC ESC的IO GROUP单节点故障后,由于一个IO GROUP是同一套缓存,会造成写缓存DISABLE,这样对于中低端存储来说,可能会出现性能些许下降,但不明显和致命。
3.对于SVC hyperswap的IO GROUP单节点故障,则好了许多,两站点都有双节点保护,站点与站点间的写缓存均独立,而且还有读写性能优化方式,如连续10分钟读写I/O占比75%以上则改变主从VDISK方式等。
【问题3】
SVC存储网关双活形式与控制器双活(HDS\NETAPP\华为)间有何优劣
【问题解答】单单从双活形式来说,一个IO GROUP的两个SVC节点的双活和存储控制器双活实现原理都是类似的,都是两个节点间的缓存同步和锁排斥机制实现的,但是SVC先进的地方是两个节点可以拉伸至两个站点,存储控制器两个节点是实现不了的。
三、双活数据中心间链路与带宽方面
【议题1】双活数据中心建设过程中,最大的难点是双中心间链路带宽,时延和抖动,各位有什么深入的见解?如何更充分地考虑,需要注意的点有哪些?应如何尽量避免该问题,高可用的链路该如何设计?各位专家对此有何深入见解?
【观点一】链路带宽,时延,抖动,这是由运营商线路质量设备决定的,用户对这块只能加大监控,束手无策,没法改变
【观点二】建议两个数据中心距离不要超过100km,同时采用至少两条以上的不同运营商线路
【观点三】考虑到运营商的光缆质量问题,使用双运营商的链路,且距离不宜超过60KM
【观点四】链路的抖动 我深有体会 !
在一个客户现场 ~两个双活数据中心~夸中心做的hacmp.~需要同时访问两个中心的存储 ~中间运营商的链路有比较大的衰减 ——12到14吧 好像!这种衰减 都tcpip这种传输 没有什么影响 但是对 光纤的传输就 影像大了~主机访问存储时好时坏!Vg被锁 影像业务!
所以 我觉得在硬件层面做灾备双活 不是很可靠 尤其是光纤的!
还是做数据库那种dataguard好像更靠谱
【观点五】dataguard据我所知是数据库事物日志的复制技术,如果采用同步的方式,TCPIP效率较低,跨中心同步复制可能会影响性能,而且数据库日志复制技术并不能覆盖数据库的全部操作,像XML和LOB格式的字段数据的增删改操作,是不会记日志的,有些应用为了效率的提升,采用了不记数据库日志的方式。但是数据库日志复制技术可以从事物层面保证数据库一致性,而通过存储链路作为数据传输通道的存储复制技术是从存储BLOCK层保证数据一致性的,差距可想而知。
【观点六】1、取决于运营商,应该选不同的两家运营商。
2、距离不宜过远。(50km以内比较好)
3、分业务,不是特别重要的 ,做主备即可,特别重要的可以考虑双活。
【观点七】从大家描述中,基本都是选择了不同的两家运营商,距离姑且不谈,毕竟仁者见仁,智者见智,但是两家运营商的裸光纤基本都在同一弱电井中,即使两家都采用了各自裸光纤的冗余,但是当前丢地铁啊,修路啊,改造啊,建设啊非常常见,两家运营商的裸光纤同时断,或者几条衰减很大,几条又断了的情况屡见不鲜,而在双活建设当中,中间链路是重中之重。
【观点八】链路问题不可预估,也很难改善,做好监控,想办法降低RPO,这样双活才有意义
【议题2】如何实时监控双活数据中心链路状况,避免因链路突发性故障或者性能衰减导致重大故障,如何应急?
如果采用了双活数据中心架构,该采用哪种技术或者软件监控双数据中心链路状况?遇到突发状况,该采取哪些措施应急处置?
【观点1】监控链路本身还不如去监控业务本身,比如交易响应时间,峰值等,出现交易堵塞失败,毕竟一切都是为了业务应用服务的,必要的应急预案应该是在是建设双活数据中心上线前,需要做的大量的场景测试,编写应急手册。遇到类似的问题,根据业务和技术评估,采取如何的应急方案.
【观点2】链路监控是必须的,但是链路监控一般运营商决定的,我们在我们的出口上可以监控到带宽情况,这样来推理,可以看出带宽是否满足需求,是否有抖动。
【观点3】链路监控一般是运营商去做的,客户自己可能做不到,但客户自己的应用运行状况,存储运行状况可以监控到的
【问题1】
双活数据中心建设过程中,双中心间链路带宽的选择,链路采用的形式等方面,从用户的角度那些更好一些?
比如采用那种方式,多少带宽可以基本满足双活中心的要求?
链路采用的形式,是采用用户全部租用运营商的链路+传输设备?还是只租用运营商的链路,而双中心的传输设备按用户要求来实现配置等?希望各位专家和同仁共同探讨,给一些建议。
【问题解答一】个人意见
1.双活数据中心”所需网络的最低带宽取决于两个方面,一是存储SAN网络,二是IP网络。SAN网络带宽取决于本地存储+同城存储写入I/O吞吐量,这个吞吐量在建设双活数据中心时,会同步写至另一站点,这个可以在本地和同城进行监控和评估;IP网络带宽取决于你双活的形式,如果是数据库双活,就需要评估和监控跨站点两个数据库间数据传输的网络吞吐,如果是应用双活,就需评估跨站点间两个应用间数据共享的网络吞吐,还应该考虑应用是就近站点读写本地数据库,还是跨站点读写,还有应用间交互是就近站点读写,还是跨站点交互读写,根据双活数据中心“双活”的等级进行提前规划、监控和整体评估,这是个浩大的工程。
2.链路采用的形式一般是只租用运营商的链路,双中心的传输设备自己购买和配置,这样更灵活又控制成本。
【问题解答二】这个问题我觉得还是主要看双活中心存储和应用的需要了,存储双活,存储之间同步链路需求最低带宽多少,应用如果是oracle rtt 时间是多少,而且中间链路延迟等等,得综合考虑
【问题解答三】第一,双活中心建立起来,基础数据同步完成
第二、计算所有业务每天的数据量有多大。
第三、测试运营商带宽速度和稳定性
第四、计算比如千兆网络把 ,一秒最多100m出头,总数据量去除就得出你的带宽,然后要考虑抖动,延迟,和高峰期,适量的加点富裕即可
保证以上4点,我认为比较合理,不是拍脑袋上。
【问题2】
SVC双活时FC交换机中间链路问题
有实施过程中关于生产中心与灾备中心间链路,是否有最佳实践。
FC交换机间链路最多支持几条?
自建光缆需注意哪些问题?
【问题解答】1.链路最佳实践,目前没有,我已列议题,希望各位专家提出自己的见解:双活数据中心建设过程中,最大的难点是双中心间链路带宽,时延和抖动,各位有什么深入的见解?
2.FC交换机之间的级联线建议是2条,做绑定,并且提升带宽。
3.一般是租用用运营商的光缆,多家运营商互备,自建的也太有钱了吧。
四、虚拟化云时代,是采用分布式还是集中式管理方面
【议题1】虚拟化云时代,民主还是集权,如何在集权过程中,进一步加强稳定性和高可用?在虚拟化云时代,集中化、虚拟化、资源池和弹性动态伸缩等都成为其代名词,但是我们感觉到业务系统越来越集中,使用的资源全部来自虚拟化过后的资源。如存储通过SVC虚拟化,单台物理机资源集中化,GPFS文件系统NSD格式化等等,越来越多的鸡蛋都集中在一个篮子里了,各位专家对此有何看法和观点,欢迎共同探讨!
【观点一】建议一般对资源池进行集中管理比较稳妥,业务系统需要直接申请资源就可以了,而且集中管理,,统一监控,同时对设备的生命周期,运行状况都能实时观察到!
【观点二】我觉得不能拍脑袋上,具体还得看业务类型,有得业务不适合集中,该分散就分散,不然中心压力过大,但是总路线肯定是重视中心,弱化分支
【观点三】集中便于管理,但带来故障影响的风险会增高,根据业务来找到平衡点,另外开始就需要考虑高可用的问题,否则后期会有巨大隐患
【观点四】这里的集中或分散主要是从物理设备的使用角度来考虑的,集中会带来管理方便和效率的提高,分散看起来分散了物理设备故障带来的风险。但我认为并不尽然,我们的非功能性业务目标一般有提高效率目标和实现客户需求的可用性目标两方面。集中虚拟化毋庸置疑能够提高效率,而良好的可用性管理也可以实现在集中虚拟化环境下的业务可用性目标,例如业务系统的可用性架构、物理设备的配置使用策略、恢复管理等等都影响着是否能达到客户需求目标。同时,集中虚拟化后,我们可以用更经济更有效的手段来协助可用性管理。因此,我认为我们需要从业务目标出发,通过可用性管理来实现可用性目标,物理设备集中化只是其中的一个因素,需要考虑但并非一个硬的限制。
【观点五】民主还是集权,永恒的话题。鸡蛋到底是放在一个篮子里?还是多放几个篮子?真的很难选择,但是在虚拟化云时代,集中化、虚拟化、资源池和弹性动态伸缩等都成为其代名词。但是我们也有担忧,也有忧虑,比如说SVC虚拟化,之前主机访问各自存储,分门别类,部分主机访问高端存储,部分主机访问中端存储,部分主机访问低端存储,SVC虚拟化上了之后,所有异构、高中低端存储均挂在至SVC,被SVC管理,再通过SVC虚拟化成VDISK,映射给所有主机使用,鸡蛋基本全在一个篮子里了,SVC集权后,核心地位无可比拟。而且在私有云建设当中,存储挂载至SVC并不是通过IMAGE模式(透穿模式),而是manage模式,说白了这种模式下存储全是SVC的LUN资源,SVC再在这些LUN资源上再虚拟化一层,再映射给主机使用,在这种模式下,主机只能识别SVC的vdisk,存储的上的卷已经完全无法单独供主机使用,这也是一种集权,地位又提升一大截,风险提升了。再比如说资源池,之前主机分散至不同的物理机中,为了动态弹性伸缩扩展,为了快速部署,快速迭代等,一台物理机资源容量越来越大,放置多个主机在一台物理机中,主机不再拥有自己的I/O卡,主机不再拥有自己的硬盘,所有的网络访问和I/O访问均需要通过虚拟I/O主机进行,主机拥有的只不过是其他主机虚拟化之后的产物,这台物理机也是一种集权,地位也提升了,风险也提升了;再比如说GPFS共享文件系统,利用该软件搭建应用系统,可以在应用端实现应用读写双活。但是GPFS软件将主机识别的盘格式化了,成了GPFS本身拥有的NSD格式盘,不属于该GPFS集群架构的主机,是无法识别NSD格式盘的,该数据盘脱离GPFS软件、脱离GPFS集群架构的主机也无法单独使用,这也是一种集权。
以上种种情况说明,我们的企业在构建双活数据中心、私有云平台的过程中,是不断集权过程,不断提升了便利性、灵活性和高可用性同时,也提升了集权者的地位,加剧了风险。为了防范风险,SVC版本不断更新,增加新的功能,新的理念,新的架构,渐渐的有了SVC Local VDM来防范存储单点风险,有了SVC Stretched Cluster来防范站点风险,有了SVC HyperSWAP来防范站点单SVC节点风险,同时缔造了基于存储虚拟化方案的SVC双活架构方案;为了防范主机过于集中的风险,我们不断利用软件层的双活方案和可靠性方案,如WAS集群、TSA+GPFS、HACMP、DB2 HADR+TSA等等,主机端利用动态迁移、vmotion等技术共同来缓解主机的集中风险压力,并不断提高资源池高可用,不断提高资源池网络及存储I/O性能等;为了防范GPFS的风险,我们将GPFS NSD数据盘通过SVC PPRC复制至灾备,并在灾备端新增了GPFS集群主机,加固该架构的冗余性和可靠性,减轻了GPFS NSD格式化后的风险压力。
可以预见的是,随着资源池不断云化,主机不断集中化,虚拟化技术不断叠加,技术不断更新,我们的高可用理念和双活架构不断更新,集中还是民主这个话题会被渐渐遗忘,在集中化中民主,在民主化中集中。
五、SVC同城容灾与异地容灾方面
【问题1】
【疑问一】双活数据中心+灾备模式的方案有哪些可以落地的?
假如客户没有异构存储需求的前提下,需要在同城建设基于存储的双活以及在异地还要做远程存储复制,IBM 除了DS8000(成本较高)以外,还有可选方案吗?
【问题解答一】如果没有异构存储,可以通过存储自身的镜像软件来实现,也可以通过系统的lvm方式来实现,或者如果客户采用了gpfs那就更好了
【疑问二】相关厂商存储本身就能实现,无需GPFS之类的;而且只是要求存储实现,不要求通过数据库实现,好像IBM的方案不多吧。没有虚拟化的要求,为何提供SVC或VPLEX呀?
【问题解答二】高端存储DS8000系列+hyperswap+GM实现要求,排除DS800系列的话,可以结合存储数据级容灾和软件层应用双活来实现你的要求,如MM+GM实现数据级同城容灾和异地灾备,应用双活可以用应用负载+GPFS或者应用负载+WAS集群等实现,数据库双活可以用GPFS+ORACLE RAC或者DB2 PURESCALE+GPFS等,数据库异地可以用DB2 HADR或者ORACLE DG
【问题解答三】除去软件层的解决方案、存储虚拟化的解决方案,这种存储的双活+异地只能是高端存储了,IBM不就是DS8000系列高端吗,那么只能是通过DS8000+HYPERSWAP实现同城双活,但是既然是用了HYPERSWAP,就无法用存储实现容灾了,只能又配合软件层的方案实现异地了。其他存储厂商高端系列估计也有方案,接触不多。
【问题2】
【疑问】灾备系统建设在满足监管要求的RTO、TPO外,有哪几种建设方式的初期成本投入最少?
【问题解答】这个问题比较泛,要看你现有的架构和设备情况,还要考虑你的可靠性、性能、扩展等要求。
最小投入的话,那么只能实现数据级灾备。
1.用备份的方式可能会最少投入,如将生产数据库、操作系统、文件通过备份至存储中,然后用异步的方式传输至灾备中心,比如说NAS与NAS间IP异步传输的方式。这个可以是初步的方式。但是RPO和RTO可能是达不到要求的,因为要采用备份恢复的方式,数据必然存在丢失,恢复时间也有点长。
2.要么是用存储的异步复制方式(需要看存储型号,还有LICENSE等)
3.要么就上SVC,将本地的异构存储整合,再利用本地SVC与灾备的V5000/V7000/SVC采用异步复制的方式
4.上SVC与SVC间的PPRC实时同步方式,实现所有异构存储的数据级同步方式。
5.假定只实现数据库级灾备,在灾备买个存储和主机,如ORACLE可以用ORACLE DG,DB2可以用HADR等实现。
个人建议和想法,供参考。
【问题3】
【疑问】如何利用svc进行异地容灾建设?
目前,数据中心内包括EMC、DELL、IBM等厂家存储,用于不同的生产系统,每套生产系统都是独立的SAN架构网络。如果采用SVC进行异地容灾建设,对于数据中心现有系统架构岂不是改动很大,并且系统还需要停机时间对吧。对于这种情况,方案应该怎样设计才能使得数据中心内现有架构改动最小,除了利用svc还有其他解决办法吗?
【问题解答】1.用SVC等存储虚拟化方案是改动最小的方案,用其他方案更复杂,要么用存储的异地复制功能(可能还需要买专门的LICENSE),要么用CDP先进行架构改造,再用本地和异地两套CDP的异地复制功能实现,有的存储型号可能还不能都实现异地灾备。
2.用SVC等存储虚拟化方案对以后架构的提升最明显的方案,对你企业架构云化转型最便捷的方案,新购两台SAN交换机,再利用SVC整合全部的异构存储,利用两地的SVC与SVC进行异步复制,或者用本地的SVC与异地的V7000等进行异步复制,均能实现异地灾备。
3.无论你采用哪种方案,停机肯定是要的,用SVC改造的方式你可以理解为:
改造前为:各异构存储---->HOST
改造后为:各异构存储---->SVC---->HOST,中间只不过是加了一道SVC而已,改造后你之前所有的不同SAN网络也进行了统一整合,整个架构清晰明了。
【问题4】
【疑问】云技术和云服务越来越普遍,灾备如何结合云及传统的方式进行实施,既保证安全便捷又节省初期费用投入?
【问题解答】云架构下无非这么几种:
云资源:
1.软件定义网络:目前来说,有点困难,难以落地,看今后技术进步。
2.软件定义计算节点:POWERVM,VMWARE,KVM。
3.软件定义存储:SVC和VPLEX为代表。
4.软件定义存储+计算节点:超融合架构。
云管理:
POWERVC,ICM,ICO,VCENTER,统一监控,统一备份,统一流管,自动化投产等
灾备要落地云,可参考上面的技术实施。
六、私有云建设与双活建设架构、案例方面
【议题1】双活数据中心复杂性也大大提升,有无必要?难点在哪?复杂性在哪?适用哪些企业?
双活数据中心进一步提升了业务系统的RPO和RTO,提升了双中心资源利用率,但相应地系统复杂性也大大提升,有无必要?难点在哪?复杂性在哪?适用哪些企业?
【观点1】双活的难点 不是有一个厂商的技术产品就能完成的,往往需要太多技术的协同配合完成,这就会造成了技术兼容性成熟度的考验。既然不是一个技术,那就会增加管理和运维的难度,对于一些IT技术力量的不足的企业,遇到问题,往往会很棘手,毕竟双活的数据中心本身,需要业务,IT,多部门联合才能更好地完成的,如何问题如何应急,在完美的双活都很难尽善尽美,最终还是要靠人去处理那些技术本身无法处理的问题。
【观点2】数据大集成项目(包含物理链路,硬件,系统,存储,甚至软件),难度很高。
1、重点是网络架构设计,也是难点,因为网络的架构设计合理,可以减少延迟,抖动等。
2、很有必要
3、大企业都有这个需求吧,只是看投入大小,金融行业,国庆扛得住,民企就选择性了,比如重要业务可以做,非重要业务备份即可。
现在还一个好处就是公有云可以减少一定的成本,形成双中心或者多中心。
【议题2】双活数据中心资源池中包括各类异构的存储、各类异构的X86服务器,各类异构的Power服务器,资源池,不同的虚拟化实现技术,那么如何分门别类统一进行资源池管理,跨中心的资源池又该如何统一管理呢,希望各专家提出自己的独特见解!
【观点1】目前来说采用最多的还是虚拟化技术,存储通过svc或者emc vplex实现,主机一般采用vmvare或者powervm来实现
【观点2】vmware做类是项目比较多
近两年流行的超融合技术也可以。
【问题1】
【疑问一】能给出几个双活数据中心 部署架构图吗?
【问题解答】给几个应用双活的吧
统一私有云平台:
MQ灾备+JAVA应用双活:
JAVA应用双活:
WAS应用双活:
【疑问二】看得出来,都离不开负载均衡,这些负载均衡是按什么分类的呢?
【问题解答】对,应用双活,负载均衡少不了的,按网络安全分区分类的
【问题2】
【疑问】
双活可以有应用级双活和数据库级双活,目前有没有数据库级双活的银行应用案例?对于两地三中心的建设环境下,如何进行双活建设呢?
【问题解答】1.据我所知,数据库双活还是有案例的
如前几年的山东移动的GPFS+ORACLE RAC双活
还有民生银行和交行的DB2 PURESCALE+GPFS双活
2.如果是两地三中心的话,基于SVC的的方案,HYPRE SWAP是不能用的,只能用SVC Stretch Cluster实现同城存储层的双活,再加SVC GM实现异地灾备,或者用SVC LOCAL VDM+SVC PPRC+SVC GM实现本地双存储高可用+同城灾备数据级灾备+异地灾备,同城应用双活只能用软件层的双活架构,如应用负载+GPFS跨中心双活,应用负载+跨中心WAS集群等等,数据库的话DB2 PURESCALE很不错。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞32本文隶属于专栏

作者其他文章
评论 17 · 赞 79
评论 8 · 赞 42
评论 0 · 赞 1
评论 0 · 赞 1
评论 1 · 赞 1
添加新评论4 条评论
2023-08-02 20:21
2020-09-18 20:05
2019-11-23 23:47
2019-06-14 17:11